Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, . Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры .
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Что такое нейронная сеть?
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
Нейронные сети состоят из следующих компонентов:
- входной слой, x
- произвольное количество скрытых слоев
- выходной слой, ŷ
- набор весов и смещений между каждым слоем W и b
- выбор для каждого скрытого слоя σ ; в этой работе мы будем использовать функцию активации Sigmoid
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Обучение нейронной сети
Выход ŷ простой двухслойной нейронной сети:
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как .
Каждая итерация обучающего процесса состоит из следующих шагов
- вычисление прогнозируемого выхода ŷ, называемого прямым распространением
- обновление весов и смещений, называемых
Последовательный график ниже иллюстрирует процесс:

Прямое распространение
Как мы видели на графике выше, прямое распространение - это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Функция потери
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок - это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения - найти набор весов и смещений, который минимизирует функцию потери.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции - это тангенс угла наклона функции.

Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется .
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.
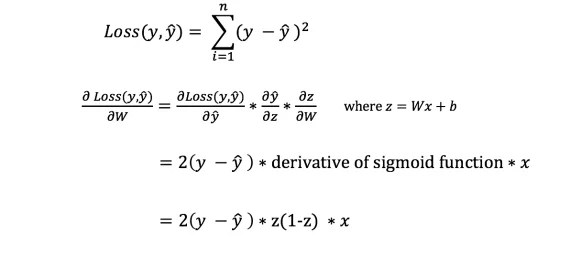
Фух! Это было громоздко, но позволило получить то, что нам нужно - производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Проверка работы нейросети
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весов Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.

Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.

Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Финальные размышления
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!
Некоторые из вас наверняка недавно проходили Stanford"ские курсы, в частности ai-class и ml-class . Однако, одно дело просмотреть несколько видео-лекций, поотвечать на вопросики quiz"ов и написать десяток программ в Matlab / Octave , другое дело начать применять полученные знания на практике. Дабы знания полученые от Andrew Ng не угодили в тот же тёмный угол моего мозга, где заблудились dft , Специальная теория относительности и Уравнение Эйлера Лагранжа , я решил не повторять институтских ошибок и, пока знания ещё свежи в памяти, практиковаться как можно больше.И тут как раз на наш сайтик приехал DDoS. Отбиваться от которого можно было админско-программерскими (grep / awk / etc) способами или же прибегнуть к использованию технологий машинного обучения.
Пример построения словаря и feature-vector"а
Предположим, мы обучаем нашу нейронную сеть всего на двух примерах: одном хорошем и одном плохом. Потом попробуем её активировать на тестовой записи.Запись из "плохого" лога:
0.0.0.0 - - "POST /forum/index.php HTTP/1.1" 503 107 "http://www.mozilla-europe.org/" "-"
Запись из "хорошего" лога:
0.0.0.0 - - "GET /forum/rss.php?topic=347425 HTTP/1.0" 200 1685 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; pl; rv:1.9) Gecko/2008052906 Firefox/3.0"
Получившийся словарь:
["__UA___OS_U", "__UA_EMPTY", "__REQ___METHOD_POST", "__REQ___HTTP_VER_HTTP/1.0", "__REQ___URL___NETLOC_", "__REQ___URL___PATH_/forum/rss.php", "__REQ___URL___PATH_/forum/index.php", "__REQ___URL___SCHEME_", "__REQ___HTTP_VER_HTTP/1.1", "__UA___VER_Firefox/3.0", "__REFER___NETLOC_www.mozilla-europe.org", "__UA___OS_Windows", "__UA___BASE_Mozilla/5.0", "__CODE_503", "__UA___OS_pl", "__REFER___PATH_/", "__REFER___SCHEME_http", "__NO_REFER__", "__REQ___METHOD_GET", "__UA___OS_Windows NT 5.1", "__UA___OS_rv:1.9", "__REQ___URL___QS_topic", "__UA___VER_Gecko/2008052906"]
Тестовая запись:
0.0.0.0 - - "GET /forum/viewtopic.php?t=425550 HTTP/1.1" 502 107 "-" "BTWebClient/3000(25824)"
Её feature-vector:
Заметьте, насколько "разрежен" (sparse) feature-vector - такое поведение будет наблюдаться для всех запросов.
Разделение Dataset"а
Хорошей практикой является разделение dataset "а на несколько частей. Я бил на две части в пропорции 70/30:- Training set . На нём мы обучаем нашу нейронную сеть.
- Test set . Им мы проверяем, насколько хорошо обучена наша нейронная сеть.
В дальнейшем, если придётся озадачиться выбором оптимальных констант, dataset надо будет разбить на 3 части в соотношении 60/20/20: Training set , Test set и Cross validation . Последний как раз и будет служить для выбора оптимальных параметров нейронной сети (например weightdecay).
Нейронная сеть в частности
Теперь, когда у нас на руках больше нет никаких текстовых логов, а есть только матрицы из feature-vector "ов, можно приступать к построению самой нейронной сети.Начнём с выбора структуры. Я выбрал сеть из одного скрытого слоя размером с удвоенный входной слой. Почему? Всё просто: так завещал Andrew Ng в случае, если не знаете с чего начать. Думаю, в дальнейшем с этим можно поиграться, порисовав графики обучения.
Функцией активации для скрытого слоя выбрана многострадальная сигмойда, а для выходного слоя - Softmax . Последний выбран на случай, если придётся делать
многоклассовую класиффикацию c mutually exclusive классами. Например, "хорошие" запросы отправлять на бэкенд, "плохие" - в бан на фаерволе, а "серые" - разгадывать капчу.
Нейронная сеть склонна к уходу в локальный минимум, поэтому у себя в коде я строю несколько сетей и выбираю ту, у которой наименьший Test error (Заметьте, именно ошибка на test set , а не trainig set).
Disclaimer
Я не настоящий сварщик. О Machine Learning я знаю только то, что подчерпнул из ml-class и ai-class. На питоне программировать начал относительно недавно, а код ниже был написан минут за 30 (время, как вы понимаете, поджимало) и в дальнейшем был лишь слегка подпилен напильником.Также этот код не самодостаточен. Ему всё равно нужна скриптовая обвязка. Например, если IP сделал N плохих запросов в течение X минут, то банить его на firewall"е.
Производительность
- lfu_cache. Портировал с ActiveState, дабы сильно ускорить обработку запросов-"высокочастотников". Down-side - повышенное потребление памяти.
- PyBrain, внезапно, написан на python и поэтому не очень быстр, однако, он может использовать ATLAS-based -модуль arac , если при создании сети указать Fast=True . Подробнее про это можно почитать в документации к PyBrain .
- Распараллеливание. Свою нейронную сеть я обучил на довольно "толстом" серверном Nehalem"е, однако, даже там чувствовалась ущербность однопоточного обучения. Можно поразмыслить на тему распараллеливания обучения нейронной сети. Простое решение - тренировать сразу несколько нейронных сетей параллельно и из них выбирать лучшую, но это создаст дополнительную нагрузку на память, что тоже не очень хорошо. Хотелось бы более универсальное решение. Возможно имеет смысл просто переписать всё на C, благо вся теоретическая база в ml-class"е была расжевана.
- Потребление памяти и кол-во features. Хорошей оптимизацией по памяти являлся переход со стндартных питоновских массивов на numpy"ные. Так же уменьшение размера dictionary и/или использование PCA может очень хорошо помочь, об этом чуть ниже.
На будущее
- Дополнительные поля в лог. В combined лог можно добавить ещё много всего, стоит подумать на тему, какие поля помогут в идентификации ботов. Возможно, имеет смысл учитывать первый октет IP адреса, ибо в не интернациональном web-проекте китайские пользователи вероятнее всего боты.
В этот раз я решил изучить нейронные сети. Базовые навыки в этом вопросе я смог получить за лето и осень 2015 года. Под базовыми навыками я имею в виду, что могу сам создать простую нейронную сеть с нуля. Примеры можете найти в моих репозиториях на GitHub. В этой статье я дам несколько разъяснений и поделюсь ресурсами, которые могут пригодиться вам для изучения.
Шаг 1. Нейроны и метод прямого распространения
Так что же такое «нейронная сеть»? Давайте подождём с этим и сперва разберёмся с одним нейроном.
Нейрон похож на функцию: он принимает на вход несколько значений и возвращает одно.
Круг ниже обозначает искусственный нейрон. Он получает 5 и возвращает 1. Ввод - это сумма трёх соединённых с нейроном синапсов (три стрелки слева).
В левой части картинки мы видим 2 входных значения (зелёного цвета) и смещение (выделено коричневым цветом).
Входные данные могут быть численными представлениями двух разных свойств. Например, при создании спам-фильтра они могли бы означать наличие более чем одного слова, написанного ЗАГЛАВНЫМИ БУКВАМИ, и наличие слова «виагра».
Входные значения умножаются на свои так называемые «веса», 7 и 3 (выделено синим).
Теперь мы складываем полученные значения со смещением и получаем число, в нашем случае 5 (выделено красным). Это - ввод нашего искусственного нейрона.

Потом нейрон производит какое-то вычисление и выдает выходное значение. Мы получили 1, т.к. округлённое значение сигмоиды в точке 5 равно 1 (более подробно об этой функции поговорим позже).
Если бы это был спам-фильтр, факт вывода 1 означал бы то, что текст был помечен нейроном как спам.

Иллюстрация нейронной сети с Википедии.
Если вы объедините эти нейроны, то получите прямо распространяющуюся нейронную сеть - процесс идёт от ввода к выводу, через нейроны, соединённые синапсами, как на картинке слева.
Шаг 2. Сигмоида
После того, как вы посмотрели уроки от Welch Labs, хорошей идеей было бы ознакомиться с четвертой неделей курса по машинному обучению от Coursera , посвящённой нейронным сетям - она поможет разобраться в принципах их работы. Курс сильно углубляется в математику и основан на Octave, а я предпочитаю Python. Из-за этого я пропустил упражнения и почерпнул все необходимые знания из видео.

Сигмоида просто-напросто отображает ваше значение (по горизонтальной оси) на отрезок от 0 до 1.
Первоочередной задачей для меня стало изучение сигмоиды , так как она фигурировала во многих аспектах нейронных сетей. Что-то о ней я уже знал из третьей недели вышеупомянутого курса , поэтому я пересмотрел видео оттуда.
Но на одних видео далеко не уедешь. Для полного понимания я решил закодить её самостоятельно. Поэтому я начал писать реализацию алгоритма логистической регрессии (который использует сигмоиду).
Это заняло целый день, и вряд ли результат получился удовлетворительным. Но это неважно, ведь я разобрался, как всё работает. Код можно увидеть .
Вам необязательно делать это самим, поскольку тут требуются специальные знания - главное, чтобы вы поняли, как устроена сигмоида.
Шаг 3. Метод обратного распространения ошибки
Понять принцип работы нейронной сети от ввода до вывода не так уж и сложно. Гораздо сложнее понять, как нейронная сеть обучается на наборах данных. Использованный мной принцип называется
Мы сейчас переживаем настоящий бум нейронных сетей. Их применяют для распознания, локализации и обработки изображений. Нейронные сети уже сейчас умеют многое что не доступно человеку. Нужно же и самим вклиниваться в это дело! Рассмотрим нейтронную сеть которая будет распознавать числа на входном изображении. Все очень просто: всего один слой и функция активации. Это не позволит нам распознать абсолютно все тестовые изображения, но мы справимся с подавляющим большинством. В качестве данных будем использовать известную в мире распознания чисел подборку данных MNIST.
Для работы с ней в Python есть библиотека python-mnist. Что-бы установить:
Pip install python-mnist
Теперь можем загрузить данные
From mnist import MNIST mndata = MNIST("/path_to_mnist_data_folder/") tr_images, tr_labels = mndata.load_training() test_images, test_labels = mndata.load_testing()
Архивы с данными нужно загрузить самостоятельно, а программе указать путь к каталогу с ними. Теперь переменные tr_images и test_images содержат изображения для тренировки сети и тестирования соотвественно. А переменные tr_labels и test_labels - метки с правильной классификацией (т.е. цифры с изображений). Все изображения имеют размер 28х28. Зададим переменную с размером.
Img_shape = (28, 28)
Преобразуем все данные в массивы numpy и нормализуем их (приведем к размеру от -1 до 1). Это увеличит точность вычислений.
Import numpy as np for i in range(0, len(test_images)): test_images[i] = np.array(test_images[i]) / 255 for i in range(0, len(tr_images)): tr_images[i] = np.array(tr_images[i]) / 255
Отмечу, что хоть и изображения принято представлять в виде двумерного массива мы будем использовать одномерный, это проще для вычислений. Теперь нужно понять "что же такое нейронная сеть"! А это просто уравнение с большим количеством коэффициентов. Мы имеем на входе массив из 28*28=784 элементов и еще по 784 веса для определения каждой цифры. В процессе работы нейронной сети нужно перемножить значения входов на веса. Сложить полученные данные и добавить смещение. Полученный результат подать на функцию активации. В нашем случае это будет Relu. Эта функция равна нулю для всех отрицательных аргументов и аргументу для всех положительных.

Есть еще много функций активации! Но это же самая простая нейронная сеть! Определим эту функцию при помощи numpy
Def relu(x): return np.maximum(x, 0)
Теперь чтобы вычислить изображение на картинке нужно просчитать результат для 10 наборов коэффициентов.
Def nn_calculate(img): resp = list(range(0, 10)) for i in range(0,10): r = w[:, i] * img r = relu(np.sum(r) + b[i]) resp[i] = r return np.argmax(resp)
Для каждого набора мы получим выходной результат. Выход с наибольшим результатом вероятнее всего и есть наше число.

В данном случае 7. Вот и все! Но нет... Ведь нужно эти самые коэффициенты где-то взять. Нужно обучить нашу нейронную сеть. Для этого применяют метод обратного распространения ошибки. Его суть в том чтобы рассчитать выходы сети, сравнить их с правильными, а затем отнять от коэффициентов числа необходимые чтобы результат был правильным. Нужно помнить, что для того чтобы вычислить эти значения нужна производная функции активации. В нашем случае она равна нулю для всех отрицательных чисел и 1 для всех положительных. Определим коэффициенты случайным образом.
W = (2*np.random.rand(10, 784) - 1) / 10 b = (2*np.random.rand(10) - 1) / 10 for n in range(len(tr_images)): img = tr_images[n] cls = tr_labels[n] #forward propagation resp = np.zeros(10, dtype=np.float32) for i in range(0,10): r = w[i] * img r = relu(np.sum(r) + b[i]) resp[i] = r resp_cls = np.argmax(resp) resp = np.zeros(10, dtype=np.float32) resp = 1.0 #back propagation true_resp = np.zeros(10, dtype=np.float32) true_resp = 1.0 error = resp - true_resp delta = error * ((resp >= 0) * np.ones(10)) for i in range(0,10): w[i] -= np.dot(img, delta[i]) b[i] -= delta[i]
В процессе обучения коэффициенты станут слегка похожи на числа:
Проверим точность работы:
Def nn_calculate(img): resp = list(range(0, 10)) for i in range(0,10): r = w[i] * img r = np.maximum(np.sum(r) + b[i], 0) #relu resp[i] = r return np.argmax(resp) total = len(test_images) valid = 0 invalid = for i in range(0, total): img = test_images[i] predicted = nn_calculate(img) true = test_labels[i] if predicted == true: valid = valid + 1 else: invalid.append({"image":img, "predicted":predicted, "true":true}) print("accuracy {}".format(valid/total))
У меня получилось 88%. Не так уж круто, но очень интересно!